
October 27, 2025
Robert "RSnake" Hansen
%20(3).png)

CVSS is a great example of institutional inertia. It began as an attempt to create a numeric shorthand for the world’s growing library of vulnerabilities. In the early days of information security, vendors, analysts, and defenders all needed a common language. The idea was noble. We wanted to create a standardized way to describe the severity of a flaw, regardless of vendor or platform.
But it turned into dogma and this post will serve to question that thinking. Let’s discuss the main problem with CVSS: The Base Score.
The Base Score was intended to capture the “qualitative severity” of a vulnerability. That means that if this bug existed in an average system, under average conditions, it should measure how “severe” that could be. Vendors could calculate it without knowing anything about your network, your mitigations, the adversaries, or your operational exposure. It was, in theory, a measure of potential impact in isolation.
But the problem is obvious the moment you state it that way: vulnerabilities never exist in isolation. They exist within a context, and that context is everything. A 9.8 in theory could be a 3.0 in practice, or vice versa. Yet, the Base Score is what gets published, consumed, and automated. It is the number that drives dashboards, SLAs, and policy decisions. And that number, by design, was never meant to be used that way.
The CVSS Special Interest Group tries to thread an impossible needle here. They insist that CVSS is not a measure of risk; it is a measure of severity. But they also claim it supports “prioritization of remediation activities” and it is “a qualitative measure of severity.” The problem is that remediation priority is, by definition, a risk-based decision. So CVSS is both not for prioritization and somehow essential to prioritization.
I think they made a serious tactical issue along the way. They allowed people to create Base Scores absent of environmental data (and threat metrics and supplemental metrics, which for the purposes of this post I’m going to collapse under the generic term “environmental” to avoid all that typing). So people assumed it had value by itself, because why would it exist otherwise? This is a huge problem for those who are confronted with this number, because it seems like you could do things like add and subtract and see which one is larger than the other and do something useful with it. You can’t do that, because it has no context.
What we’ve done, collectively, is confuse a descriptor with a decision tool. Years ago, the industry took a number that was designed to describe something and repurposed it as a justification to act on something. And because every major vulnerability feed, scanner, and compliance framework was built to depend on that number absent of environmental data, we’ve built an entire ecosystem on top of a category error.
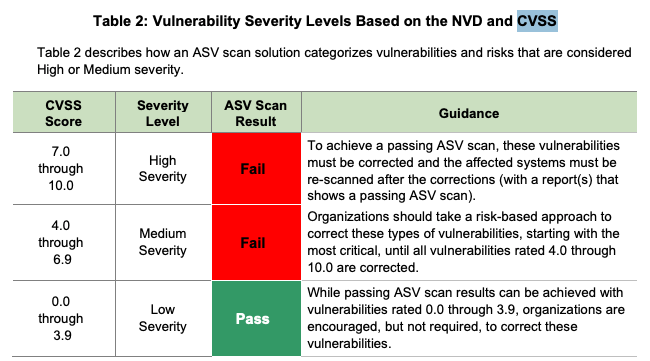
The Base Score became the world’s most widely adopted metric for “risk” even though it was never meant to be one. Frameworks like PCI-DSS require a Base Score of 4.0 or greater to be remediated (Table 1), and no one stopped them.
There is a reason we are in this spot. CVSS needed a simple, portable metric to attach to advisories. Vendors couldn’t calculate the environmental context of customers, so the Base Score was used. Hey, it’s a thing they could provide in their reports that has some reference somewhere. Over time, that convenience was codified everywhere. It became assumed to mean something deeper than it does. Auditors demanded it, dashboards were built, compliance was built to remediate “criticals” and “highs” and sometimes even “mediums” and APIs were constructed to consume the data as if it was actually meaningful as-is. The number took on a life of its own, completely disconnected from its intended use.
The Base Score has outlived its usefulness. It does not inform meaningful risk decisions, and its sheer existence continues to encourage exactly the misuse that the CVSS authors warn against. Of course its removal would be a breaking change but only to some extent. The rest of the CVSS structure could still exist and still produce a meaningful score if and only if contextual inputs are provided. But by removing the automatic computation of the Base Score when environmental context is missing, the model would force organizations to confront the reality that you can’t measure risk without context.
The counterargument, of course, is that vendors need something to publish. They need a number to communicate to the world that a flaw is serious. To quote a friend of mine, “The CVSS base score is not completely worthless. It just results in having 5 or 10 times as many vulnerabilities to fix as you really need to prioritize at a high or critical SLA.” Okay, assuming he is right, fine, but is that worth it? The honest answer is that I simply do not know.
The Base Score endures because it gives us comfort and it is theoretically easy to understand although I actually think the opposite is true. It lets us believe that there is a single scalar value that can capture the multidimensional mess of security risk without taking into account any environmental attributes. This is obviously a dangerous assumption and yet it is a common one we run up against in our conversations with VM groups. Of course it’s not that simple, is it? Because there isn’t just one Base Score as my friend told me, “People don't want to hear that there may be five different CVSS scores for your vulnerability. One from Red Hat, another from NVD, another from the open source third party component developer, and maybe a couple more from companies like Qualys and Black Duck.” So it’s not just one Base Score we’re contending with, it may be many different base scores.
If we were serious about fixing CVSS, we would probably need to remove the Base Score entirely. Force vendors to publish vector strings and descriptive context, and make the next version of the CVSS calculator (version 5) impossible to produce a number if the environmental factors aren’t present.
A pre-baked number allows for misuse, and it is precisely this number and the unscientific nature of the process, wholly absent of context, that is causing so much churn. A model that would be free of this confusion and churn would require the CVSS system to force users to apply their own environment and threat models before seeing any score at all.
To be fair, there are downsides. There is more from my friend about the challenges. He was lamenting, “10 or 20 or 30 different products to collect and list all of the vulnerabilities in your enterprise, and then dump them all in a back end system so you can sort them out”, saying “You can easily wind up with 5,000 or 10,000 vulnerabilities for one project. Who's got the resources to do an end user CVSS score for each one of those?” To his point, not only is it a huge time burden, the idea of removing the ability to calculate a Base Score without environmental data would exacerbate that issue, because now every product, not just some products, would be required to create their own Base Score.
But that brings up a very important second issue. Why is it not just possible, but likely that he would be concerned that he would wind up with different Base Scores at all? Shouldn’t they all be the same if this is in fact a qualitative score, and not at least somewhat subjective? I think it says a lot about how unscientific this process is that it is a reasonable concern that every single product might deliver a different Base Score, or somehow worse, the same score but using different variables that create that same score.
I know what I’m saying here, and I know what a huge/fundamental change that would be. I know it would be next to impossible to get the vendors to fix their systems. So do we declare bankruptcy on Base Score, or do we fix it? I’m open to ideas.
What we do know is that Base Score is being misused for risk prioritization, like in PCI-DSS, but it has no use other than for risk prioritization since severity isn’t a thing anyone cares about outside of the context of risk. The CVSS SIG tacitly approves of using CVSS’s Base Score for risk prioritization, while decrying when it is used for risk prioritization. Unless they get rid of it, it will continue to be used incorrectly. But I’m not naive. It’s not going anywhere. So, dear reader, what does that say about this whole situation and the people involved?
I know how insane all this sounds, which is why I am on the hunt for alternative paths to calculate risk.
© 2026 Root Evidence